
Reinforcement Learning continued
Thu 21 January 2021
In the last post we looked at a SARSA agent in the taxi_v3 environment in OpenAI Gym. This post we will see if we can improve on the basic SARSA agent and optimize its parameters.
One simple way to find the best parameters is to do a sweep. If you vary multiple settings also called grid search. In our case we know that the learning rate should be somewhere between 0 and 1. At lower values the agent needs more steps in the environment to learn the true value of a state, but in a stable way. At higher values the agent is faster to approach the true value, but will tend to oscillate around that true value. I started the sweep at a learning rate of 0.01 making steps to 0.02 and 0.05 up until 1.0. We ran for 10 times 3000 episodes and summed the average reward per run. In the figure below you see that for the SARSA agent code from last post a learning rate of 0.2 gives the highest (least negative) result.
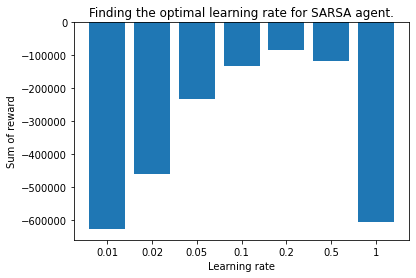
If the problem we're solving is serious I would run a second, finer sweep, some form of meta-optimization algorithm. But doing too much hyper parameter searching can also lead you to overfitting. Balance is the answer it seems.
Now the second way to improve performance of the agent, is to make it smarter, more complex. For the next experiment I implemented two changes:
- Changed the policy to use softmax. Epsilon-greedy has the advantage that it will always explore, even if the agent is very certain that one of the actions is optimal. This e-soft policy will choose a random action when the agent has very little environment information, but as it becomes clear one of the action is best in a certain situation it will increasingly prefer to choose that action.
- Change to update step to expected SARSA. This means that the expected reward is updated using the weighted probabilities of taking one of the actions. This reduces variation in learning, in theory making it faster.
I will share the code for this agent below. A downside of increasing agent complexity is that it increases computation time. A factor 2 for this experiment. In the figure below you an see that the agent achieves better reward values than the normal SARSA agent, especially at high learning rates. The previous best being about -100.000.
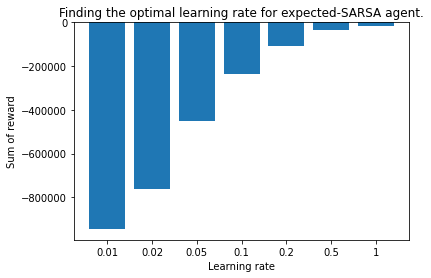
Now the best value is at the end of the sweep, good practice says that you increase your sweep range. Since the optimal value could lie outside of the original range. I set up a second sweep from 0.2 this time linearly increasing to 2.0. Normally values above 1 don't make sense since the agent will forget the previous value and replace it with an inflated value. But in this implementation the agent doesn't forget the old value by 1-LR for implementation simplicity. So let's try going slightly over.
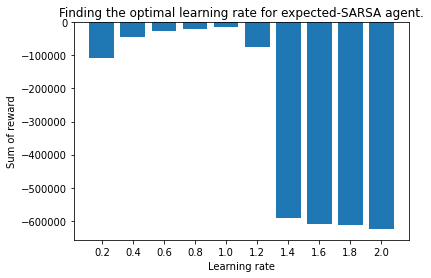
Here we see that the total reward is less negative up until 1.0, and then quickly increases again. The summed reward here is -15k. For the normal SARSA agent the best LR was 0.2 with a summed reward of -84k.
Next post I will look into tile coding. This is a technique to deal with larger an continuous environments.
Code for the expected SARSA agent with e-soft policy:
class exp_sarsa_softmax_agent():
def __init__(self, num_actions, num_states, init_val=0, learn_rate=0.2, discount=0.9):
self.num_actions = num_actions
self.num_states = num_states
self.learn_rate = learn_rate
self.discount = discount
self.Q = np.zeros((num_states, num_actions))+init_val
self.last_action = None
self.last_state = None
self.range_num_actions = list(range(num_actions))
def policy(self, state):
q_s = self.Q[state,:]
p = sp.special.softmax(q_s)
action = np.random.choice(self.range_num_actions, p=p)
return action, p
def first_step(self, state):
action, _ = self.policy(state)
self.last_action = action
self.last_state = state
return action
def step(self, state, reward):
action, p = self.policy(state)
exp_q = np.sum(self.Q[state, :]*p)
self.Q[self.last_state, self.last_action] += self.learn_rate * (reward + self.discount*exp_q - self.Q[self.last_state, self.last_action])
self.last_action = action
self.last_state = state
return action
def last_step(self, reward):
self.Q[self.last_state, self.last_action] += self.learn_rate * (reward - self.Q[self.last_state, self.last_action])